



最新下载










热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Mysql事务隔离级别原理实例解析
时间:2020-03-24 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下Mysql事务隔离级别原理实例解析,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
正文
开始先提一下,根据事务的隔离级别不同,会有三种情况发生。即脏读、不可重复读、幻读。
这里,大家记住一点,根据脏读、不可重复读、幻读定义来看,有如下包含关系:
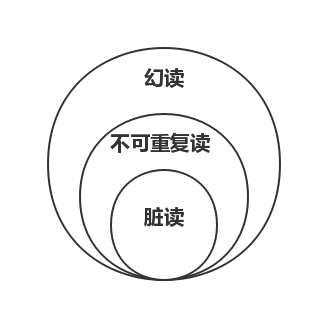
那么,这张图怎么理解呢?
即,如果发生了脏读,那么不可重复读和幻读是一定发生的。因为拿脏读的现象,用不可重复读,幻读的定义也能解释的通。但是反过来,拿不可重复读的现象,用脏读的定义就不一定解释的通了!
假设有表tx_tb如下,pId为主键

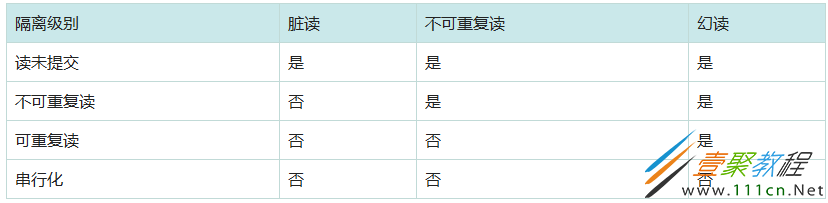
1、读未提交(READ_UNCOMMITTED)
其实这个从隔离名字就可以看出来,一个事务可以读到另一个事务未提交的数据!为了便于说明,简单的画图说明!

如图所示,一个事务检索的数据被另一个未提交的事务给修改了。
官网对脏读定义的地址为
https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_dirty_read
其内容为
**dirty read
An operation that retrieves unreliable data, data that was updated by another transaction but not yet committed.
**
翻译过来就是
检索操作出来的数据是不可靠的,是可以被另一个未提交的事务修改的!
你会发现,我们的演示结果和官网对脏读的定义一致。根据我们最开始的推理,如果存在脏读,那么不可重复读和幻读一定是存在的。
2、读已提交(READ_COMMITTED)
这个也能看的出来,一个事务能读到另一个事务已提交的数据!为了便于说明,我简单的画图说明!

如图所示,一个事务检索的数据只能被另一个已提交的事务修改。
官网对不可重复读定义的地址为
https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_non_repeatable_read
其内容为
**non-repeatable read
The situation when a query retrieves data, and a later query within the same transaction retrieves what should be the same data, but the queries return different results (changed by another transaction committing in the meantime).
**
翻译过来就是
一个查询语句检索数据,随后又有一个查询语句在同一个事务中检索数据,两个数据应该是一样的,但是实际情况返回了不同的结果。!
ps:作者注,这里的不同结果,指的是在行不变的情况下(专业点说,主键索引没变),主键索引指向的磁盘上的数据内容变了。如果主键索引变了,比如新增一条数据或者删除一条数据,就不是不可重复读。
显然,我们这个现象符合不可重复读的定义。下面,大家做一个思考:
这个不可重复读的定义,放到脏读的现象里是不是也可以说的通。显然脏读的现象,也就是**读未提交(READ_UNCOMMITTED)**的那个例子,是不是也符合在同一个事务中返回了不同结果!但是反过来就不一定通了,一个事务A中查询两次的结果在被另一个事务B改变的情况下,如果事务B未提交就改变了事务A的结果,就属于脏读,也属于不可重复读。如果该事务B提交了才改变事务A的结果,就不属于脏读,但属于不可重复读。
3、可重复读(REPEATABLE_READ)
这里,改变一下顺序,先上幻读的定义
官网对幻读定义的地址为
https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_phantom
phantom
A row that appears in the result set of a query, but not in the result set of an earlier query. For example, if a query is run twice within a transaction, and in the meantime, another transaction commits after inserting a new row or updating a row so that it matches the WHERE clause of the query.
翻译过来就是
在一次查询的结果集里出现了某一行数据,但是该数据并未出现在更早的查询结果集里。例如,在一次事务里进行了两次查询,同时另一个事务插入某一行或更新某一行数据后(该数据符合查询语句里where后的条件),并提交了!
好了,接下来上图,大家自己评定该现象是否符合幻读的定义

显然,该现象是符合幻读的定义的。同一事务的两次相同查询出现不同行。下面,大家做一个思考:
这个幻读的定义,放到不可重复读的现象里是不是也可以说的通。大家自行思考!反过来就不一定通了。事务第二次查询出了一个数据,但是该数据并未出现在第一次查询的结果集里。如果该数据是修改数据,那么该现象既属于不可重复读,也属于幻读。如果该数据是新增或删除的数据,那该现象就不属于不可重复读,但属于幻读。
接下来说一下,为什么很多文章都产生误传,说是可重复读可以解决幻读问题!原因出自官网的一句话
(地址是:https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-record-locks)
原文内容如下
By default, InnoDB operates in REPEATABLE READ transaction isolation level. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows (see Section 14.7.4, “Phantom Rows”).
按照原本这句话的意思,应该是
InnoDB默认用了REPEATABLE READ。在这种情况下,使用next-key locks解决幻读问题!
结果估计,某个国内翻译人员翻着翻着变成了
InnoDB默认用了REPEATABLE READ。在这种情况下,可以解决幻读问题!
然后大家继续你抄我,我抄你,结果你懂的!
显然,漏了"使用了next-key locks!"这个条件后,意思完全改变,我们在该隔离级别下执行语句
select * from tx_tb where pId >= 1;
是快照读,是不加任何锁的,根本不能解决幻读问题,除非你用
select * from tx_tb where pId >= 1 lock in share mode;
这样,你就用上了next-key locks,解决了幻读问题!
4、串行读(SERIALIZABLE_READ)
在该隔离级别下,所有的select语句后都自动加上lock in share mode。因此,在该隔离级别下,无论你如何进行查询,都会使用next-key locks。所有的select操作均为当前读!

OK,注意看上表红色部分!就是因为使用了next-key locks,innodb将PiD=1这条索引记录,和(1,++∞)这个间隙锁住了。其他事务要在这个间隙上插数据,就会阻塞,从而防止幻读发生!
有的人会说,你这第二次查询的结果,也变了啊,明显和第一次查询结果不一样啊?对此,我只能说,请看清楚啊。这是被自己的事务改的,不是被其他事物修改的。这不算是幻读,也不是不可重复读。
-
上一个: SQL注入漏洞过程代码实例及解决方法
相关文章
- MySQL登录、访问及退出操作解析 10-18
- sql语句 update字段null不能用is null问题解析 09-28
- SQL Server ISNULL 不生效原因及解决分析 09-28
- 关于if exists的用法及说明分析 09-28
- Mysql删除某个字段的最后四个字符 09-26
- mysql多个字段最大最小值介绍 09-26