



最新下载










热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Python for循环及基础用法代码详解
时间:2019-11-09 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下Python for循环及基础用法代码详解,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
Python 中的循环语句有 2 种,分别是 while 循环和 for 循环,本节给大家介绍 for 循环,它常用于遍历字符串、列表、元组、字典、集合等序列类型,逐个获取序列中的各个元素。
for 循环的语法格式如下:
for 迭代变量 in 字符串|列表|元组|字典|集合:
代码块
格式中,迭代变量用于存放从序列类型变量中读取出来的元素,所以一般不会在循环中对迭代变量手动赋值;代码块指的是具有相同缩进格式的多行代码(和 while 一样),由于和循环结构联用,因此代码块又称为循环体。
for 循环语句的执行流程如图 1 所示。
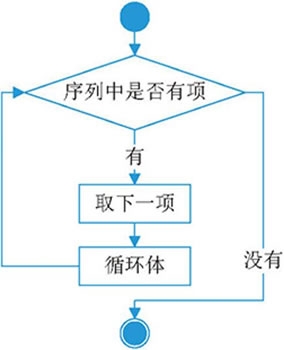
图 1 for 循环语句的执行流程图
例如:
name = '张三' #变量name,逐个输出各个字符 for ch in name: print(ch)
运行结果为:
张
三
可以看到,使用 for 循环遍历 “张三” 字符串的过程中,迭代变量 ch 先后被赋值为‘张'和‘三',并代入循环体中运行,只不过例子中的循环体比较简单,只有一行输出代码。
for 进行数值循环
在使用 for 循环时,最基本的应用就是进行数值循环。比如说,想要实现从 1 到 100 的累加,可以执行如下代码:
print("计算 1+2+...+100 的结果为:")
#保存累加结果的变量
result = 0
#逐个获取从 1 到 100 这些值,并做累加操作
for i in range(101):
result += i
print(result)
运行结果为:
计算 1+2+...+100 的结果为:
5050
上面代码中,使用了 range() 函数,此函数是 Python 内置的函数,用于生成一系列连续的整数,多用于 for 循环中。
range() 函数的语法格式如下:
range(start,end,step)
此函数中各参数的含义如下:
start:用于指定计数的起始值,如果省略不写,则默认从 0 开始。
end:用于指定计数的结束值(不包括此值),此参数不能省略。
step:用于指定步长,即两个数之间的间隔,如果省略,则默认步长为 1。
总之,在使用 range() 函数时,如果只有一个参数,则表示指定的是 end;如果有两个参数,则表示指定的是 start 和 end。
大家也可以根据需要写代码测试一下。
例如:
print("输出10 以内的所有奇数:")
for i in range(1,10,2):
print(i,end=' ')
运行结果为:
输出10 以内的所有奇数:
1 3 5 7 9
在 Python 2.x 中,除提供 range() 函数外,还提供了一个 xrange() 函数,它可以解决 range() 函数不经意间耗掉所有可用内存的问题。但在 Python 3.x 中,已经将 xrange() 更名为 range() 函数,并删除了老的 xrange() 函数。
for 循环遍历列表和元组
在使用 for 循环遍历列表和元组时,列表或元组有几个元素,for 循环的循环体就执行几次,针对每个元素执行一次,迭代变量会依次被赋值为元素的值。
如下代码使用 for 循环遍历元组:
a_tuple = ('crazyit', 'fkit', 'Charlie')
for ele in a_tuple:
print('当前元素是:', ele)
运行结果为:
当前元素是: crazyit
当前元素是: fkit
当前元素是: Charlie
当然,也可按上面方法来遍历列表。例如,下面程序要计算列表中所有数值元素的总和、平均值:
src_list = [12, 45, 3.4, 13, 'a', 4, 56, 'crazyit', 109.5]
my_sum = 0
my_count = 0
for ele in src_list:
# 如果该元素是整数或浮点数
if isinstance(ele, int) or isinstance(ele, float):
print(ele)
# 累加该元素
my_sum += ele
# 数值元素的个数加1
my_count += 1
print('总和:', my_sum)
print('平均数:', my_sum / my_count)
运行结果为:
12
45
3.4
13
4
56
109.5
总和: 242.9
平均数: 34.7
上面程序使用 for 循环遍历列表的元素,并对几何元素进行判断:只有当列表元素是数值(int、float)时,程序才会累加它们,这样就可以计算出列表中数值元素的总和。
不仅如此,程序中还使用了 Python 的 isinstance() 函数,该函数用于判断某个变量是否为指定类型的实例,其中前一个参数是要判断的变量,后一个参数是类型。我们可以在 Python 的交互式解释器中测试该函数的功能,例如如下运行过程:
>>> isinstance(2,int)
True
>>> isinstance('a',int)
False
>>> isinstance('a',str)
True
从上面的运行过程可以看出,使用 isinstance() 函数判断变量是否为指定类型非常方便、有效。
如果需要,for 循环也可根据索引来遍历列表或元组,即只要让迭代变量取 0 到列表长度的区间,就可通过该迭代变量访问列表元素。例如如下程序:
a_list = [330, 1.4, 50, 'fkit', -3.5]
# 遍历0到len(a_list)的范围
for i in range(0, len(a_list)) :
# 根据索引访问列表元素
print("第%d个元素是 %s" % (i , a_list[i]))
运行结果为:
第0个元素是 330
第1个元素是 1.4
第2个元素是 50
第3个元素是 fkit
第4个元素是 -3.5
for 循环遍历字典
使用 for 循环遍历字典其实也是通过遍历普通列表来实现的。前面在介绍字典时己经提到,字典包含了如下三个方法:
items():返回字典中所有 key-value 对的列表。
keys():返回字典中所有 key 的列表。
values():返回字典中所有 value 的列表。
因此,如果要遍历字典,完全可以先调用字典的上面三个方法之一来获取字典的所有 key-value 对、所有 key、所有 value,再进行遍历。如下程序示范了使用 for 循环来遍历字典:
my_dict = {'语文': 89, '数学': 92, '英语': 80}
# 通过items()方法遍历所有key-value对
# 由于items方法返回的列表元素是key-value对,因此要声明两个变量
for key, value in my_dict.items():
print('key:', key)
print('value:', value)
print('-------------')
# 通过keys()方法遍历所有key
for key in my_dict.keys():
print('key:', key)
# 在通过key获取value
print('value:', my_dict[key])
print('-------------')
# 通过values()方法遍历所有value
for value in my_dict.values():
print('value:', value)
运行结果为:
key: 语文
value: 89
key: 数学
value: 92
key: 英语
value: 80
-------------
key: 语文
value: 89
key: 数学
value: 92
key: 英语
value: 80
-------------
value: 89
value: 92
value: 80
上面程序通过三个 for 循环分别遍历了字典的所有 key-value 对、所有 key、所有 value。尤其是通过字典的 items() 遍历所有的 key-value 对时,由于 items() 方法返回的是字典中所有 key-value 对组成的列表,列表元素都是长度为 2 的元组,因此程序要声明两个变量来分别代表 key、value(这也是序列解包的应用)。
假如需要实现一个程序,用于统计列表中各元素出现的次数。由于我们并不清楚列表中包含多少个元素,因此考虑定义一个字典,以列表的元素为 key,该元素出现的次数为 value。程序如下:
src_list = [12, 45, 3.4, 12, 'fkit', 45, 3.4, 'fkit', 45, 3.4]
statistics = {}
for ele in src_list:
# 如果字典中包含ele代表的key
if ele in statistics:
# 将ele元素代表出现次数加1
statistics[ele] += 1
# 如果字典中不包含ele代表的key,说明该元素还未出现过
else:
# 将ele元素代表出现次数设为1
statistics[ele] = 1
# 遍历dict,打印出各元素的出现次数
for ele, count in statistics.items():
print("%s的出现次数为:%d" % (ele, count))
运行结果为:
12的出现次数为:2
45的出现次数为:3
3.4的出现次数为:3
fkit的出现次数为:2
python循环-for循环综合小案例
一、字符串的反转
# 翻转字符—将“我是个大好人!我爱我的家”反转“家的我爱我!人好大个是我” yuanJu = "我是个大好人!我爱我的家" result = "" # 第一步,先拆字 for x in yuanJu: # 用遍历出的结果与空字符串相加 result = x + result print(result)
二、打印1—100之间的偶数
# 打印 1—100之间的偶数
# 首先创建一个1—100的集合,利用range函数,生成的半开半闭的区间,所以最后得+1。
num = range(1, 101)
for n in num:
if n % 2 == 0:
print(n)
else:
print("以上数字为1-100之内的偶数")
因为上面的偶数需要包括100,所以range(1,101).
相关文章
- Golang ProtoBuf的基本语法详解 10-20
- Python识别MySQL中的冗余索引解析 10-20
- Python+Pygame绘制小球代码展示 10-18
- Python中的数据精度问题介绍 10-18
- Python随机值生成的常用方法介绍 10-18
- python3解压缩.gz文件分析 09-27