



最新下载









热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Python3.x+迅雷x自动下载高分电影实现代码示例
时间:2020-01-12 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下Python3.x+迅雷x自动下载高分电影实现代码示例,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
最终实现效果:
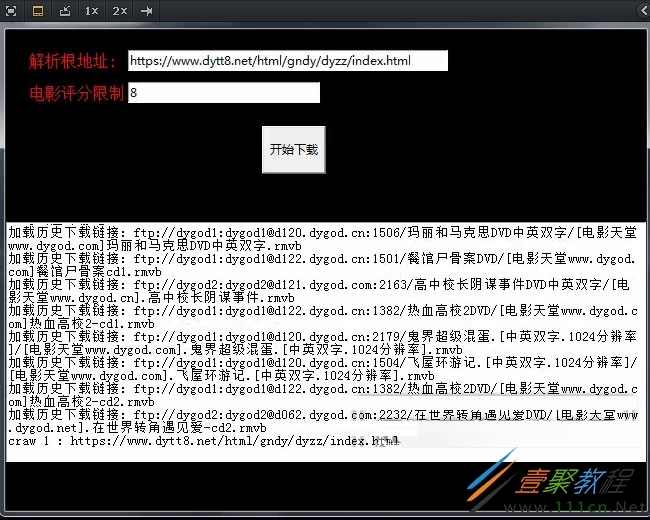
如上,这个下载工具是有界面的,只要输入一个根地址和电影评分,就可以自动爬电影了,要完成这个工具需要具备以下知识点:
tkinter这是个Python GUI开发的库,图中这个简陋的可怜的界面就是基于TK开发的,不想要界面也可以去掉,丝毫不影响爬电影,加上用户界面可以显得屌一点,当然最主要的是我想学习一点新知识静态网页的分析技巧相对于动态网站的爬取,静态网站的爬取就显得小菜了,F12会按吧,右键查看网页源代码会吧,通过这些简单的操作就可以查看网页的排版布局规则,然后根据这些规则写爬虫,soeasy
数据持久化已经下载过的电影,下次再爬电影的时候不希望再下载一次吧,那就把下载过的链接存储起来,下载电影之前去比对是否下载过,以过滤重复下载
requests+BeautifulSoup的使用,re正则,Python数据类型,Python线程,dbm、pickle等数据持久化库的使用,等等,这个工具也就这么些知识范畴了。当然,Python是面向对象的,编程思想是所有语言通用的,这个不是一朝一夕的事,也没办法通过语言描述清楚。各位对号入座,以上哪个知识面不足的自己去翻资料学习,这可是直接贴代码的。
import url_manager
import html_parser
import html_download
import persist_util
from tkinter import *
from threading import Thread
import os
class SpiderMain(object):
def __init__(self):
self.mUrlManager = url_manager.UrlManager()
self.mHtmlParser = html_parser.HtmlParser()
self.mHtmlDownload = html_download.HtmlDownload()
self.mPersist = persist_util.PersistUtil()
# 加载历史下载链接
def load_history(self):
history_download_links = self.mPersist.load_history_links()
if history_download_links is not None and len(history_download_links) > 0:
for download_link in history_download_links:
self.mUrlManager.add_download_url(download_link)
d_log("加载历史下载链接: " + download_link)
# 保存历史下载链接
def save_history(self):
history_download_links = self.mUrlManager.get_download_url()
if history_download_links is not None and len(history_download_links) > 0:
self.mPersist.save_history_links(history_download_links)
def craw_movie_links(self, root_url, score=8):
count = 0;
self.mUrlManager.add_url(root_url)
while self.mUrlManager.has_continue():
try:
count = count + 1
url = self.mUrlManager.get_url()
d_log("craw %d : %s" % (count, url))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
'Referer': url
}
content = self.mHtmlDownload.down_html(url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_urls, next_link = self.mHtmlParser.parser_movie_link(doc)
if movie_urls is not None and len(movie_urls) > 0:
for movie_url in movie_urls:
d_log('movie info url: ' + movie_url)
content = self.mHtmlDownload.down_html(movie_url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_name, movie_score, movie_xunlei_links = self.mHtmlParser.parser_movie_info(doc, score=score)
if movie_xunlei_links is not None and len(movie_xunlei_links) > 0:
for xunlei_link in movie_xunlei_links:
# 判断该电影是否已经下载过了
is_download = self.mUrlManager.has_download(xunlei_link)
if is_download == False:
# 没下载过的电影添加到迅雷下载列表
d_log('开始下载 ' + movie_name + ', 链接地址: ' + xunlei_link)
self.mUrlManager.add_download_url(xunlei_link)
os.system(r'"D:迅雷ThunderProgramThunder.exe" {url}'.format(url=xunlei_link))
# 每下载一部电影都实时更新数据库,这样可以保证即使程序异常退出也不会重复下载该电影
self.save_history()
if next_link is not None:
d_log('next link: ' + next_link)
self.mUrlManager.add_url(next_link)
except Exception as e:
d_log('错误信息: ' + str(e))
def runner(rootLink=None, scoreLimit=None):
if rootLink is None:
return
spider = SpiderMain()
spider.load_history()
if scoreLimit is None:
spider.craw_movie_links(rootLink)
else:
spider.craw_movie_links(rootLink, score=float(scoreLimit))
spider.save_history()
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/index.html'
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/list_23_207.html'
def start(rootLink, scoreLimit):
loop_thread = Thread(target=runner, args=(rootLink, scoreLimit,), name='LOOP THREAD')
#loop_thread.setDaemon(True)
loop_thread.start()
#loop_thread.join() # 不能让主线程等待,否则GUI界面将卡死
btn_start.configure(state='disable')
# 刷新GUI界面,文字滚动效果
def d_log(log):
s = log + 'n'
txt.insert(END, s)
txt.see(END)
if __name__ == "__main__":
rootGUI = Tk()
rootGUI.title('XX电影自动下载工具')
# 设置窗体背景颜色
black_background = '#000000'
rootGUI.configure(background=black_background)
# 获取屏幕宽度和高度
screen_w, screen_h = rootGUI.maxsize()
# 居中显示窗体
window_x = (screen_w - 640) / 2
window_y = (screen_h - 480) / 2
window_xy = '640x480+%d+%d' % (window_x, window_y)
rootGUI.geometry(window_xy)
lable_link = Label(rootGUI, text='解析根地址: ',
bg='black',
fg='red',
font=('宋体', 12),
relief=FLAT)
lable_link.place(x=20, y=20)
lable_link_width = lable_link.winfo_reqwidth()
lable_link_height = lable_link.winfo_reqheight()
input_link = Entry(rootGUI)
input_link.place(x=20+lable_link_width, y=20, rel.5)
lable_score = Label(rootGUI, text='电影评分限制: ',
bg='black',
fg='red',
font=('宋体', 12),
relief=FLAT)
lable_score.place(x=20, y=20+lable_link_height+10)
input_score = Entry(rootGUI)
input_score.place(x=20+lable_link_width, y=20+lable_link_height+10, rel.3)
btn_start = Button(rootGUI, text='开始下载', command=lambda: start(input_link.get(), input_score.get()))
btn_start.place(relx=0.4, rely=0.2, rel.1, rel.1)
txt = Text(rootGUI)
txt.place(rely=0.4, rel, rel.5)
rootGUI.mainloop()
spider_main.py,主代码入口,主要是tkinter实现的一个简陋的界面,可以输入根地址,电影最低评分。所谓的根地址就是某天堂网站的一类电影的入口,比如进入首页有如下的分类,最新电影、日韩电影、欧美影片、2019精品专区,等等。这里以2019精品专区为例(https://www.dytt8.net/html/gndy/dyzz/index.html),当然,用其它的分类地址入口也是可以的。评分就是个过滤电影的条件,要学会对垃圾电影说不,浪费时间浪费表情,你可以指定大于等于8分的电影才下载,也可以指定大于等于9分等,必须输入数字哈,输入些乱七八糟的东西进去程序会崩溃。
'''
URL链接管理类,负责管理爬取下来的电影链接地址,包括新解析出来的链接地址,和已经下载过的链接地址,保证相同的链接地址只会下载一次
'''
class UrlManager(object):
def __init__(self):
self.urls = set()
self.used_urls = set()
self.download_urls = set()
def add_url(self, url):
if url is None:
return
if url not in self.urls and url not in self.used_urls:
self.urls.add(url)
def add_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_url(url)
def has_continue(self):
return len(self.urls) > 0
def get_url(self):
url = self.urls.pop()
self.used_urls.add(url)
return url
def get_download_url(self):
return self.download_urls
def has_download(self, url):
return url in self.download_urls
def add_download_url(self, url):
if url is None:
return
if url not in self.download_urls:
self.download_urls.add(url)
url_manager.py,注释里写的很清楚了,基本上每个py文件的关键地方都写了比较详细的注释
import requests
from requests import Timeout
'''
HtmlDownload,通过一个链接地址将该html页面整体down下来,然后通过html_parser.py解析其中有价值的信息
'''
class HtmlDownload(object):
def __init__(self):
self.request_session = requests.session()
self.request_session.proxies
def down_html(self, url, retry_count=3, headers=None, proxies=None, data=None):
if headers:
self.request_session.headers.update(headers)
try:
if data:
content = self.request_session.post(url, data=data, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
else:
content = self.request_session.get(url, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
except (ConnectionError, Timeout) as e:
print('HtmlDownload ConnectionError or Timeout: ' + str(e))
if retry_count > 0:
self.down_html(url, retry_count-1, headers, proxies, data)
return None
except Exception as e:
print('HtmlDownload Exception: ' + str(e))
html_download.py,就是用requests将静态网页的内容整体down下来
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
import urllib.parse
import base64
'''
html页面解析器
'''
class HtmlParser(object):
# 解析电影列表页面,获取电影详情页面的链接
def parser_movie_link(self, content):
try:
urls = set()
next_link = None
doc = BeautifulSoup(content, 'lxml')
div_content = doc.find('div', class_='co_content8')
if div_content is not None:
tables = div_content.find_all('table')
if tables is not None and len(tables) > 0:
for table in tables:
link = table.find('a', class_='ulink')
if link is not None:
print('movie name: ' + link.text)
movie_link = urljoin('https://www.dytt8.net', link.get('href'))
print('movie link ' + movie_link)
urls.add(movie_link)
next = div_content.find('a', text=re.compile(r".*?下一页.*?"))
if next is not None:
next_link = urljoin('https://www.dytt8.net/html/gndy/dyzz/', next.get('href'))
print('movie next link ' + next_link)
return urls, next_link
except Exception as e:
print('解析电影链接地址发生错误: ' + str(e))
# 解析电影详情页面,获取电影详细信息
def parser_movie_info(self, content, score=8):
try:
movie_name = None # 电影名称
movie_score = 0 # 电影评分
movie_xunlei_links = set() # 电影的迅雷下载地址,可能存在多个
doc = BeautifulSoup(content, 'lxml')
movie_name = doc.find('title').text.replace('迅雷下载_电影天堂', '')
#print(movie_name)
div_zoom = doc.find('div', id='Zoom')
if div_zoom is not None:
# 获取电影评分
span_txt = div_zoom.text
txt_list = span_txt.split('◎')
if txt_list is not None and len(txt_list) > 0:
for tl in txt_list:
if 'IMDB' in tl or 'IMDb' in tl or 'imdb' in tl or 'IMdb' in tl:
txt_score = tl.split('/')[0]
print(txt_score)
movie_score = re.findall(r"d+.?d*", txt_score)
if movie_score is None or len(movie_score) <= 0:
movie_score = 1
else:
movie_score = movie_score[0]
print(movie_name + ' IMDB影片分数: ' + str(movie_score))
if float(movie_score) < score:
print('电影评分低于' + str(score) + ', 忽略')
return movie_name, movie_score, movie_xunlei_links
txt_a = div_zoom.find_all('a', href=re.compile(r".*?ftp:.*?"))
if txt_a is not None:
# 获取电影迅雷下载地址,base64转成迅雷格式
for alink in txt_a:
xunlei_link = alink.get('href')
'''
这里将电影链接转换成迅雷的专用下载链接,后来发现不转换迅雷也能识别
xunlei_link = urllib.parse.quote(xunlei_link)
xunlei_link = xunlei_link.replace('%3A', ':')
xunlei_link = xunlei_link.replace('%40', '@')
xunlei_link = xunlei_link.replace('%5B', '[')
xunlei_link = xunlei_link.replace('%5D', ']')
xunlei_link = 'AA' + xunlei_link + 'ZZ'
xunlei_link = base64.b64encode(xunlei_link.encode('gbk'))
xunlei_link = 'thunder://' + str(xunlei_link, encoding='gbk')
'''
print(xunlei_link)
movie_xunlei_links.add(xunlei_link)
return movie_name, movie_score, movie_xunlei_links
except Exception as e:
print('解析电影详情页面错误: ' + str(e))
html_parser.py,用bs4解析down下来的html页面内容,根据网页规则过去我们需要的东西,这是爬虫最重要的地方,写爬虫的目的就是想要取出对我们有用的东西。
import dbm
import pickle
import os
'''
数据持久化工具类
'''
class PersistUtil(object):
def save_data(self, name='No Name', urls=None):
if urls is None or len(urls) <= 0:
return
try:
history_db = dbm.open('downloader_history', 'c')
history_db[name] = str(urls)
finally:
history_db.close()
def get_data(self):
history_links = set()
try:
history_db = dbm.open('downloader_history', 'r')
for key in history_db.keys():
history_links.add(str(history_db[key], 'gbk'))
except Exception as e:
print('遍历dbm数据失败: ' + str(e))
return history_links
# 使用pickle保存历史下载记录
def save_history_links(self, urls):
if urls is None or len(urls) <= 0:
return
with open('DownloaderHistory', 'wb') as pickle_file:
pickle.dump(urls, pickle_file)
# 获取保存在pickle中的历史下载记录
def load_history_links(self):
if os.path.exists('DownloaderHistory'):
with open('DownloaderHistory', 'rb') as pickle_file:
return pickle.load(pickle_file)
else:
return None
persist_util.py,数据持久化工具类。
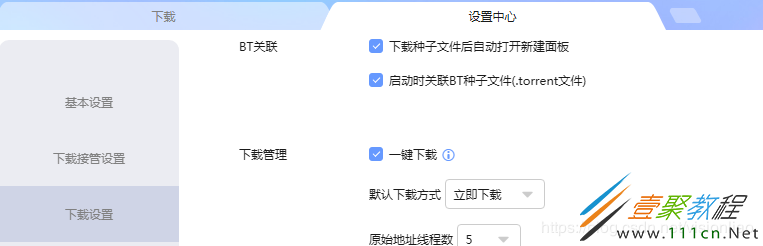
这样代码部分就完成了,说下迅雷,一定要如下图一样在迅雷设置打开一键下载功能,否则每次新增一个下载任务都会弹出用户确认框的,还有就是调用迅雷下载资源的代码:os.system(r'"D:迅雷ThunderProgramThunder.exe" {url}'.format(url=xunlei_link)),一定要去到迅雷安装目录找到Thunder.exe文件,不能用快捷方式的地址(我的电脑->迅雷->右键属性->目标,迅雷X这里显示的路径是快捷方式的路径,不能用这个),否则找不到程序。
相关文章
- Golang ProtoBuf的基本语法详解 10-20
- Python识别MySQL中的冗余索引解析 10-20
- Python+Pygame绘制小球代码展示 10-18
- Python中的数据精度问题介绍 10-18
- Python随机值生成的常用方法介绍 10-18
- python3解压缩.gz文件分析 09-27