



最新下载









热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
MySQL中的insert ignore into使用代码示例
时间:2022-08-18 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下MySQL中的insert ignore into使用代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
最近工作中,使用到了insert ignore into语法,感觉这个语法还是挺有用的,就记录下来做个总结。
insert ignore into: 忽略重复的记录,直接插入数据。
包括两种场景:
1、插入的数据是主键冲突时
insert ignore into会给出warnings,show warnings就可以看到提示主键冲突;
[test]> create table tt(c1 int primary key, c2 varchar(50))engine = xx; Query OK, 0 rows affected (0.21 sec) [test]> insert into tt values(1, "aaa"), (2, "bbb"), (3, "ccc"); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 [test]> select * from tt; +----+------+ | c1 | c2 | +----+------+ | 1 | aaa | | 2 | bbb | | 3 | ccc | +----+------+ 3 rows in set (0.01 sec) [test]> [test]> insert ignore into tt values(1, "aaa"), (2, "bbb"), (3, "ccc"); Query OK, 0 rows affected, 3 warnings (0.01 sec) Records: 3 Duplicates: 3 Warnings: 3 [test]> [test]> select * from tt; +----+------+ | c1 | c2 | +----+------+ | 1 | aaa | | 2 | bbb | | 3 | ccc | +----+------+ 3 rows in set (0.00 sec)
使用insert ignore into语句时,如果主键冲突,只是提示"warnings"。
如果使用insert into语句时,如果主键冲突直接报错。
2、没有主键冲突时,直接插入数据
insert into 与 insert ignore into 都是直接插入数据
[test]> create table t2(c1 int, c2 varchar(50))engine = xxx; Query OK, 0 rows affected (0.05 sec) [test]> insert into t2 values(1, "aaa"), (2, "bbb"), (3, "ccc"); Query OK, 3 rows affected (0.03 sec) Records: 3 Duplicates: 0 Warnings: 0 GreatDB Cluster[test]> select * from t2; +------+------+ | c1 | c2 | +------+------+ | 1 | aaa | | 2 | bbb | | 3 | ccc | +------+------+ 3 rows in set (0.00 sec) [test]> insert into t2 values(1, "aaa"), (2, "bbb"), (3, "ccc"); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 [test]> insert into t2 values(1, "aaa"), (2, "bbb"), (3, "ccc"); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 [test]> select * from t2; +------+------+ | c1 | c2 | +------+------+ | 1 | aaa | | 2 | bbb | | 3 | ccc | | 1 | aaa | | 2 | bbb | | 3 | ccc | | 1 | aaa | | 2 | bbb | | 3 | ccc | +------+------+ 9 rows in set (0.00 sec) [test]> insert ignore into t2 values(1, "aaa"), (2, "bbb"), (3, "ccc"); Query OK, 3 rows affected (0.03 sec) Records: 3 Duplicates: 0 Warnings: 0
因此,insert ignore into主要是忽略重复的记录,直接插入数据。
insert ignore into--跳坑
首先,SQL语句:
insert ignore into term(term) VALUES (#{term})
然后,数据库表:
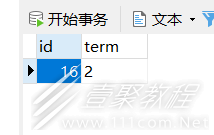
简单的不能再简单的一张表:解释一下,id是自增的,同时也是主键,term就是term喽,其他的外键、索引什么的都没有。
要求是:不能使term重复插入;
刚开始认为就是判断的插入的数据是否重复,然后发现不是这样的,它判断的是主键或者索引是否重复(更准确的来说是忽略主键冲突时报的错误)。
所以在这里要说说这个自增的id了,因为在insert ignore into插入的时候你的现在将要插入的数据的id已经是增加一了,所以你的这个自增主键id是无论如何也不能相等的,所以自然你的数据也就不会听话的把重复的数据不插入,这也就是为什么,即使ignore时没有插入数据它的自增的键也会跳过,所以这个要注意。
解决办法就是添加个索引就欧克了呗

因为重复的时候它的自增的键依然会增加,所以当数据的重复率很高的时候,可以考虑把自增的键搞成自己控制的一个因素,手动自增,岂不美滋滋?
-
上一个: MySQL中游标和绑定变量代码示例
-
下一个: Redisson加锁解锁代码实现方法
相关文章
- MySQL登录、访问及退出操作解析 10-18
- sql语句 update字段null不能用is null问题解析 09-28
- SQL Server ISNULL 不生效原因及解决分析 09-28
- 关于if exists的用法及说明分析 09-28
- Mysql删除某个字段的最后四个字符 09-26
- mysql多个字段最大最小值介绍 09-26