



最新下载










热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Python怎么制作自动下载百度图片爬虫
时间:2018-02-28 编辑:简简单单 来源:一聚教程网
Python也是编程使用非常广泛的一门设计语言,那么使用Python怎么制作自动下载百度图片爬虫,这种制作效果也是很受大家喜欢,下面我们就来了解下制作爬虫的具体操作方法。
Python制作自动下载百度图片爬虫
制作一个爬虫一般分以下几个步骤:
-
分析需求
-
分析网页源代码,配合开发者工具
-
编写正则表达式或者XPath表达式
-
正式编写 python 爬虫代码
效果预览
运行效果如下:
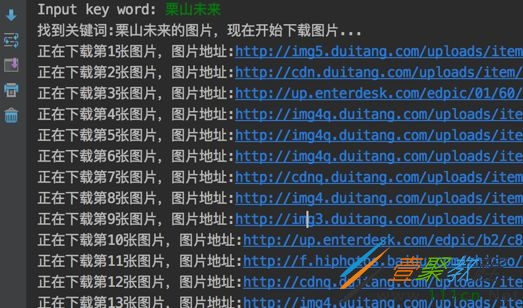
存放图片的文件夹:

需求分析
我们的爬虫至少要实现两个功能:一是搜索图片,二是自动下载。
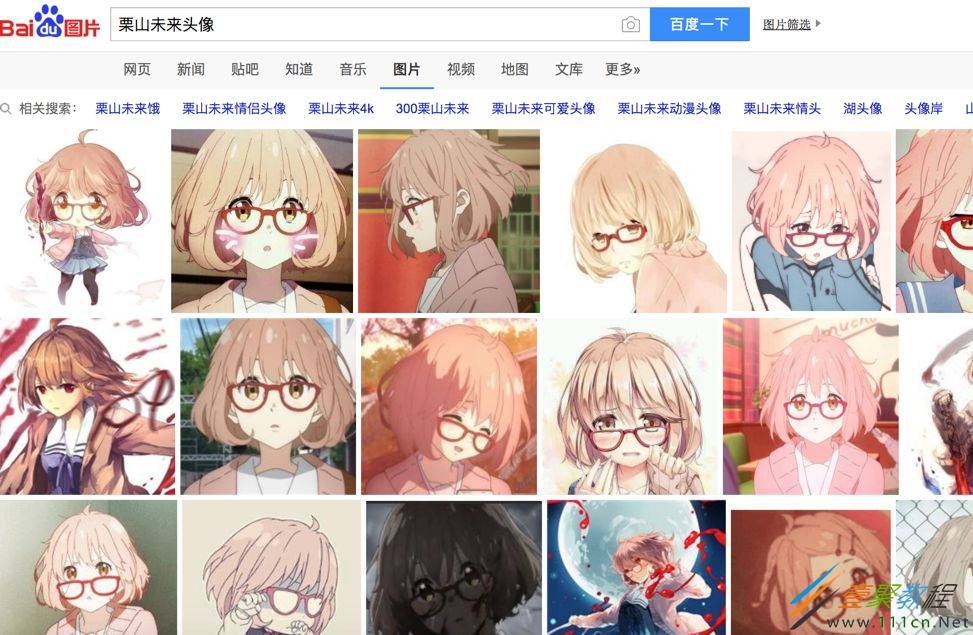
搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片看看:

随便搜索几个关键字,可以看到已经搜索出来很多张图片:
分析网页
我们点击右键,查看源代码:
打开源代码之后,发现一堆源代码比较难找出我们想要的资源。
这个时候,就要用开发者工具!我们回到上一页面,调出开发者工具,我们需要用的是左上角那个东西:(鼠标跟随)。
然后选择你想看源代码的地方,就可以发现,下面的代码区自动定位到了相应的位置。如下图:
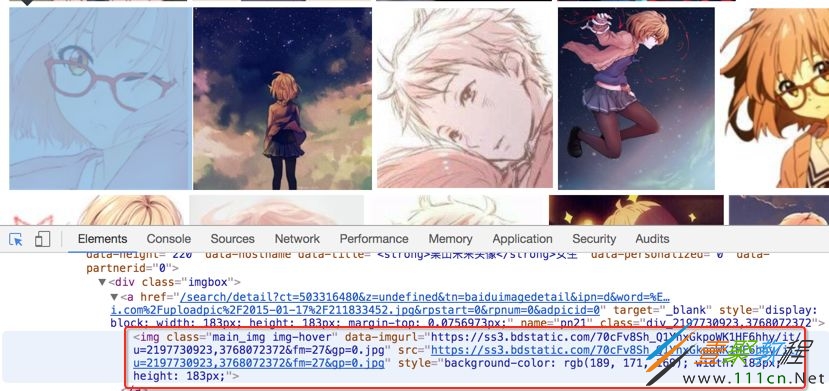

我们复制这个地址,然后到刚才的一堆源代码里搜索一下,发现了它的位置,但是这里我们又疑惑了,这个图片有这么多地址,到底用哪个呢?我们可以看到有thumbURL,middleURL,hoverURL,objURL

通过分析可以知道,前面两个是缩小的版本,hoverURL 是鼠标移动过后显示的版本,objURL 应该是我们需要的,可以分别打开这几个网址看看,发现 objURL 的那个最大最清晰。
找到了图片地址,接下来我们分析源代码。看看是不是所有的 objURL 都是图片。
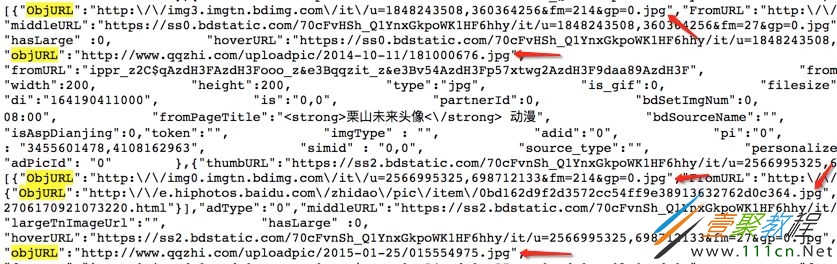
发现都是以.jpg格式结尾的图片。
编写正则表达式
-
pic_url=re.findall(''objURL':'(.*?)',',html,re.S)
编写爬虫代码
这里我们用了2个包,一个是正则,一个是 requests 包
-
#-*- coding:utf-8 -*-
-
importre
-
importrequests
复制百度图片搜索的链接,传入 requests ,然后把正则表达式写好

-
url='https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5%E5%A4%B4%E5%83%8F&ct=201326592&ic=0&lm=-1&
-
html=requests.get(url).text
-
pic_url=re.findall(''objURL':'(.*?)',',html,re.S)
因为有很多张图片,所以要循环,我们打印出结果来看看,然后用 requests 获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
-
pic_url=re.findall(''objURL':'(.*?)',',html,re.S)
-
i=1
-
foreachinpic_url:
-
printeach
-
try:
-
pic=requests.get(each,timeout=10)
-
exceptrequests.exceptions.ConnectionError:
-
print('【错误】当前图片无法下载')
-
continue
接着就是把图片保存下来,我们事先建立好一个 images 目录,把图片都放进去,命名的时候,以数字命名。
-
dir='../images/'+keyword+'_'+str(i)+'.jpg'
-
fp=open(dir,'wb')
-
fp.write(pic.content)
-
fp.close()
-
i+=1
完整的代码
-
# -*- coding:utf-8 -*-
-
importre
-
importrequests
-
defdowmloadPic(html,keyword):
-
pic_url=re.findall(''objURL':'(.*?)',',html,re.S)
-
i=1
-
print('找到关键词:'+keyword+'的图片,现在开始下载图片...')
-
foreachinpic_url:
-
print('正在下载第'+str(i)+'张图片,图片地址:'+str(each))
-
try:
-
pic=requests.get(each,timeout=10)
-
exceptrequests.exceptions.ConnectionError:
-
print('【错误】当前图片无法下载')
-
continue
-
dir='../images/'+keyword+'_'+str(i)+'.jpg'
-
fp=open(dir,'wb')
-
fp.write(pic.content)
-
fp.close()
-
i+=1
-
if__name__=='__main__':
-
word=input('Input key word: ')
-
url='http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&ct=201326592&v=flip'
-
result=requests.get(url)
-
dowmloadPic(result.text,word)
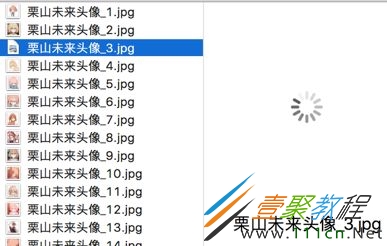

我们看到有的图片没显示出来,打开网址看,发现确实没了。

因为百度有些图片它缓存到百度的服务器上,所以我们在百度上还能看见它,但它的实际链接已经失效了。
总结
enjoy 我们的第一个图片下载爬虫吧!当然它不仅能下载百度的图片,依葫芦画瓢,你现在应该能做很多事情了,比如爬取头像,爬淘宝展示图等等。
完整代码已经放到Github上: https://github.com/nnngu/LearningNotes
相关文章
- Golang ProtoBuf的基本语法详解 10-20
- Python识别MySQL中的冗余索引解析 10-20
- Python+Pygame绘制小球代码展示 10-18
- Python中的数据精度问题介绍 10-18
- Python随机值生成的常用方法介绍 10-18
- python3解压缩.gz文件分析 09-27