



最新下载










热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
利用python爬取有道词典方法代码示例
时间:2020-12-08 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下利用python爬取有道词典方法代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
主要内容
材料
1.Python 3.8.4
2.电脑一台
3.Google浏览器(其他的也行,但我是用的Google)
写程序前准备
打开Google浏览器,找的有道词典的翻译网页(http://fanyi.youdao.com/)
打开后摁F12打开开发者模式,找Network选项卡,点击Network选项卡,然后刷新一下网页
然后翻译一段文字,随便啥都行(我用的程序员的传统:hello world),然后点击翻译
在选项卡中找到以translate开头的post文件
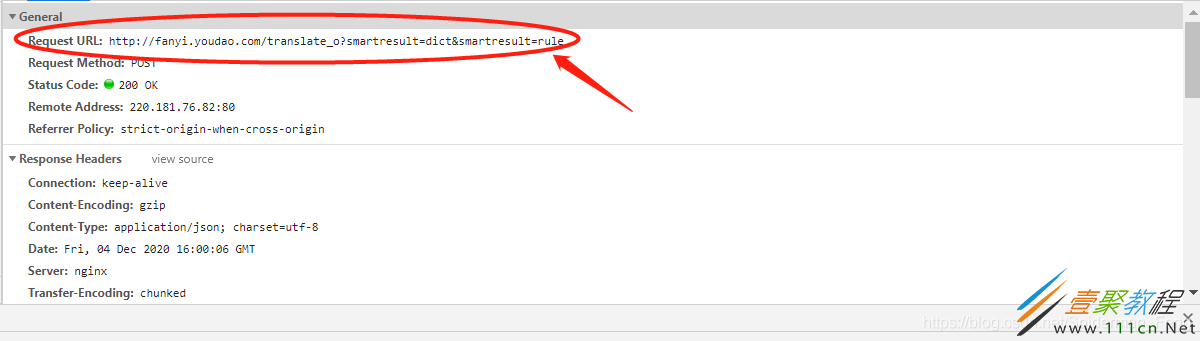
箭头的地方才是真正的提交地址
记住他,写代码时要用

这个是提交电脑的基本信息,记住他,等会儿要用,等会儿伪装成电脑时可以用,因为电脑会有基本信息,而如果是python的话会显示成python3.8.4(因为我的版本是3.8.4),从而容易被服务器禁入

等会儿还要用
好,准备工作做完了,接下来开始干正事了
开始编写爬虫代码
代码如下:
#导入urllib库
import urllib.request
import urllib.parse
import json
while True: #无限循环
content = input("请输入您要翻译的内容(输入 !!! 退出程序): ")
#设置退出条件
if content == '!!!':
break
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #选择要爬取的网页,上面找过了
#加上一个帽子,减少被发现的概率(下面head列表的内容就是上面找的)
head = {}
head['User - Agent'] = '请替换'
#伪装计算机提交翻译申请(下面的内容也在在上面有过,最好根据自己的进行修改)
data = {}
data['type'] = 'AUTO'
data['i'] = content
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom:'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url, data)
#解码
html = response.read().decode('utf-8')
paper = json.loads(html)
#打印翻译结果
print("翻译结果: %s" % (paper['translateResult'][0][0]['tgt']))
运行结果

-
上一个: Python之字符串的遍历4种方式代码
相关文章
- Golang ProtoBuf的基本语法详解 10-20
- Python识别MySQL中的冗余索引解析 10-20
- Python+Pygame绘制小球代码展示 10-18
- Python中的数据精度问题介绍 10-18
- Python随机值生成的常用方法介绍 10-18
- python3解压缩.gz文件分析 09-27